
컴파일링
#include <stdio.h>
int main(void)
{
printf("hello, world\n")
}C 언어로 만든 파일을 실행시키려면 아래 clang 명령어로 ‘컴파일’을 시켜줘야합니다.
clang -o hello hello.c이 명령어를 치면 파일이 컴파일 되면서 컴퓨터가 읽을 수 있는 0과 1로 가득찬 파일 hello.out 을 생성하여 실행 가능하게 합니다.
위 예시처럼 C에서 make나 clang을 사용해서 프로그램을 실행할 때 아래 네 개의 단계를 거칩니다.
- 전처리
- 컴파일링
- 어셈블링
- 링킹
전처리(Precompile)
컴파일의 전체 과정은 네 단계로 나누어볼 수 있습니다. 그 중 첫 번째 단계는 전처리인데, 전처리기에 의해 수행됩니다. # 으로 시작되는 C 소스 코드는 전처리기에게 실질적인 컴파일이 이루어지기 전에 무언가를 실행하라고 알려줍니다.
예를 들어, #include는 전처리기에게 다른 파일의 내용을 포함시키라고 알려줍니다. 프로그램의 소스 코드에 #include 와 같은 줄을 포함하면, 전처리기는 새로운 파일을 생성하는데 이 파일은 여전히 C 소스 코드 형태이며 stdio.h 파일의 내용이 #include 부분에 포함됩니다.
컴파일(Compile)
전처리기가 전처리한 소스 코드를 생성하고 나면 그 다음 단계는 컴파일입니다. 컴파일러라고 불리는 프로그램은 C 코드를 어셈블리어라는 저수준 프로그래밍 언어로 컴파일합니다.
어셈블리는 C보다 연산의 종류가 훨씬 적지만, 여러 연산들이 함께 사용되면 C에서 할 수 있는 모든 것들을 수행할 수 있습니다. C 코드를 어셈블리 코드로 변환시켜줌으로써 컴파일러는 컴퓨터가 이해할 수 있는 언어와 최대한 가까운 프로그램으로 만들어 줍니다. 컴파일이라는 용어는 소스 코드에서 오브젝트 코드로 변환하는 전체 과정을 통틀어 일컫기도 하지만, 구체적으로 전처리한 소스 코드를 어셈블리 코드로 변환시키는 단계를 말하기도 합니다.
어셈블(Assemble)
소스 코드가 어셈블리 코드로 변환되면, 다음 단계인 어셈블 단계로 어셈블리 코드를 오브젝트 코드로 변환시키는 것입니다. 컴퓨터의 중앙처리장치가 프로그램을 어떻게 수행해야 하는지 알 수 있는 명령어 형태인 연속된 0과 1들로 바꿔주는 작업이죠. 이 변환작업은 어셈블러라는 프로그램이 수행합니다. 소스 코드에서 오브젝트 코드로 컴파일 되어야 할 파일이 딱 한 개라면, 컴파일 작업은 여기서 끝이 납니다. 그러나 그렇지 않은 경우에는 링크라 불리는 단계가 추가됩니다.
링크(Link)
만약 프로그램이 여러 개의 파일(라이브러리 include 등)로 이루어져 있어 하나의 오브젝트 파일로 합쳐져야 한다면 링크라는 컴파일의 마지막 단계가 필요합니다. 링커는 여러 개의 다른 오브젝트 코드 파일을 실행 가능한 하나의 오브젝트 코드 파일로 합쳐줍니다. 예를 들어, 컴파일을 하는 동안에 CS50 라이브러리를 링크하면 오브젝트 코드는 GetInt()나 GetString() 같은 함수를 어떻게 실행할 지 알 수 있게 됩니다.
이 네 단계를 거치면 최종적으로 실행 가능한 파일이 완성됩니다.
배열(1)
메모리
C에는 아래와 같은 여러 자료형이 있고, 각각의 자료형은 서로 다른 크기의 메모리를 차지합니다.
bool: 불리언, 1바이트char: 문자, 1바이트int: 정수, 4바이트float: 실수, 4바이트long: (더 큰) 정수, 8바이트double: (더 큰) 실수, 8바이트string: 문자열, ?바이트
컴퓨터 안에는 아래 사진과 같은 RAM 이라고 하는 물리적 칩이 메모리 역할을 합니다.
쉽게 생각하면 아래 사진에서 여러 개의 노란색 사각형이 메모리를 의미하고, 작은 사각형 하나가 1바이트를 의미한다고 볼 수 있습니다.

예를 들어 char 타입의 변수를 하나 생성하고, 그 값을 입력한다고 하면 위 사진에서 한 사각형 안에 그 변수의 값이 저장되는 것이죠.
배열
세 개의 점수를 저장하고 그 평균을 출력하는 프로그램을 만들어 봅시다. 점수를 하나하나 하드코딩할 수 있지만, 점수의 개수가 더 많아진다면 이 프로그램은 많은 부분을 수정해야 합니다. 대신 ‘배열’ 이라는 자료형을 사용할 수 있습니다.
배열은 같은 자료형의 데이터를 메모리상에 연이어서 저장하고 이를 하나의 변수로 관리하기 위해 사용됩니다.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
// Scores
int scores[3];
scores[0] = 72;
scores[1] = 73;
scores[2] = 33;
// Print average
printf("Average: %i\n", (scores[0] + scores[1] + scores[2]) / 3);
}int scores[3];이라는 코드는 int 자료형을 가지는 크기 3의 배열을 scores 라는 이름으로 생성하겠다는 의미입니다.- 배열의 인덱스는 0부터 시작하기 때문에, scores의 인덱스는 0, 1, 2 세 개가 있습니다.
- 이 인덱스를 변수명 뒤 대괄호 [ ] 사이에 입력하여 배열의 원하는 위치에 원하는 값을 저장하고 불러올 수 있습니다.
하지만 위와 같은 코드는 여전히 점수의 개수가 바뀌는 상황에서 제약이 많습니다.
배열(2)
전역변수
아래 코드에서 scores 배열의 크기를 정해주는 N이라는 변수를 새로 선언하였습니다.
만약 N이 고정된 값(상수)이라면 그 값을 선언할 때 const를 앞에 붙여서 전역 변수, 즉 코드 전반에 거쳐 바뀌지 않는 값임을 지정해줄 수 있습니다.
관례적으로 이런 전역 변수의 이름은 대문자로 표기 합니다.
#include <cs50.h>
#include <stdio.h>
const int N = 3;
int main(void)
{
// 점수 배열 선언 및 값 저장
int scores[N];
scores[0] = 72;
scores[1] = 73;
scores[2] = 33;
// 평균 점수 출력
printf("Average: %i\n", (scores[0] + scores[1] + scores[2]) / N);
}배열의 동적 선언 및 저장
const 라는 고정된 변수를 사용하면 결과도 항상 고정되어있습니다. 아래 코드에서와 같이 루프와 함수를 선언하여 좀 더 동적인 프로그램을 작성할 수 있습니다.
#include <cs50.h>
#include <stdio.h>
float average(int length, int array[]);
int main(void)
{
// 사용자로부터 점수의 갯수 입력
int n = get_int("Scores: ");
// 점수 배열 선언 및 사용자로부터 값 입력
int scores[n];
for (int i = 0; i < n; i++)
{
scores[i] = get_int("Score %i: ", i + 1);
}
// 평균 출력
printf("Average: %.1f\n", average(n, scores));
}
//평균을 계산하는 함수
float average(int length, int array[])
{
int sum = 0;
for (int i = 0; i < length; i++)
{
sum += array[i];
}
return (float) sum / (float) length;
}여기서는 배열의 크기를 사용자에게 직접 입력 받고, 배열의 크기만큼 루프를 돌면서 각 인덱스에 해당하는 값을 역시 사용자에게 동적으로 입력 받아 저장합니다. 그리고 average 라는 함수를 따로 선언하여 평균을 구합니다.
average 함수는 length 와 array[], 즉 배열의 길이와 배열을 입력으로 받습니다. 함수 안에서는 배열의 길이만큼 루프를 돌면서 값의 합을 구하고 최종적으로 평균값을 반환합니다.
문자열과 배열
c에서 문자열(string) 자료형의 데이터는 사실 문자(char) 자료형의 데이터들의 배열입니다.
string s = “HI!”; 과 같이 문자열 s가 정의되어 있다고 생각해봅시다.
s는 문자의 배열이기 때문에 메모리상에 아래 그림과 같이 저장되고, 인덱스로 각 문자에 접근할 수 있습니다.
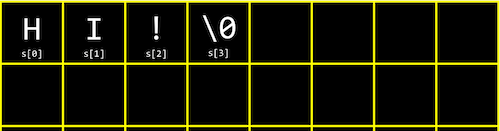
여기서 가장 끝의 ‘\0’은 문자열의 끝을 나타내는 널(NULL) 종단 문자입니다. 단순히 모든 비트가 ‘0’으로 이뤄진 1바이트를 의미합니다.
그럼 아래 코드와 같이 여러 문자열이 동시에 선언된 경우를 살펴보겠습니다.
string names[4];
names[0] = "EMMA";
names[1] = "RODRIGO";
names[2] = "BRIAN";
names[3] = "DAVID";
printf("%s\n", names[0]);
printf("%c%c%c%c\n", names[0][0], names[0][1], names[0][2], names[0][3]);names라는 문자열 형식의 배열에 네 개의 이름이 저장되어있습니다.
첫 번째 printf에서는 names의 첫번째 인덱스의 값, 즉 “EMMA”를 출력합니다.
두 번째 printf에서는 형식 지정자가 %s가 아닌 %c로 설정되어 있음을 확인할 수 있습니다. 따라서 출력하는 것은 문자열이 아닌 문자입니다. 여기서는 각 이름의 두번째 문자를 출력하고자 하는데, 이는 names[0][1]과 같이 2차원 배열을 통해 접근할 수 있습니다.
다시 말해 names[0][1]는 names의 첫 번째 값, 즉 “EMMA”라는 문자열에서, 그 두번째 값, 즉 ‘M’ 이라는 문자를 의미합니다.
아래 그림에서 names가 실제 메모리상에 저장된 예시와 해당하는 인덱스를 확인할 수 있습니다.
