
데이터베이스를 다룰 때 인덱싱(indexing)은 매우 중요하다. 본 게시글에서는 데이터베이스 인덱스의 개념과 필요성, 그리고 레일즈 앱에 적용하는 방법을 알아보려고 한다.
우리는 언제 인덱싱을 사용할까?
인덱싱이 무엇인지에 대해 살펴보기 전에, 인덱싱에 사용되는 상황을 알아보자.
웹에서는 인덱싱을 자주 사용한다:
- 게시글 상세페이지 조회 및 수정 (문자열 혹은 외래키로 사용자의 게시글 검색)
- 로그인 (이메일로 사용자 검색)
- 관계(association) 설정 (조인 테이블이나 관계 설정을 통해 게시글의 사용자 검색)
위의 모든 예시는 공통적으로 “데이터베이스에서 수 많은 데이터를 검색“하여 원하는 값을 찾는다. SQL문을 사용해 데이터베이스를 검색하는데, 복잡한 연산을 실행할수록 속도 및 성능이 악화된다. 이때, 인덱스 자료구조를 활용하여 검색 성능을 향상시킬 수 있다.
인덱스(Index)란?
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지를 찾아 보는것은 오랜 시간이 걸린다. 그렇기 때문에 책의 저자들은 책의 맨 앞 또는 맨 뒤에 색인을 추가하는데, 데이터베이스의 index는 책의 색인과 같다. 출처: [Database] 인덱스(index)란?
 |
|---|
| 이미지 출처: [Database] 인덱스(index)란? |
데이터베이스의 특정 열에 대한 인덱스는 책의 색인(Index)과 유사하게 작동한다. 특정 주제를 찾기 위해 책의 모든 페이지를 스캔하는 대신, 우리는 보통 가나다 순으로 정렬되어 있는 색인에서 그 주제를 찾는다. 색인은 책의 관련 페이지를 가리키고 있으며, 더욱 빠르게 원하는 주제를 찾을 수 있도록 도와준다.
데이터베이스 인덱스는 순서가 지정된 데이터 구조로, 데이터를 더 빨리 검색하기 위해 추가할 수 있다. 아래 예시와 같이, 검색이 필요한 데이터베이스의 특정 열에 대한 인덱스를 만들 수 있다.
아래 이미지를 참고하여 예시를 들어보자. 만약 모든 Jack 카드를 찾기 위해 뒤섞인 카드들을 찾아야 한다면, 잭을 찾을 때까지 각각의 모든 카드를 살펴봐야 할 것이다. 그러나 카드 모양(A, 2, 3, … King)으로 카드 더미를 인덱싱했다면 잭이 있어야 할 위치로 빠르게 이동하여 더 적은 검색으로 모든 잭을 찾을 수 있다.
| 이미지 출처: Database Indexes Explained |
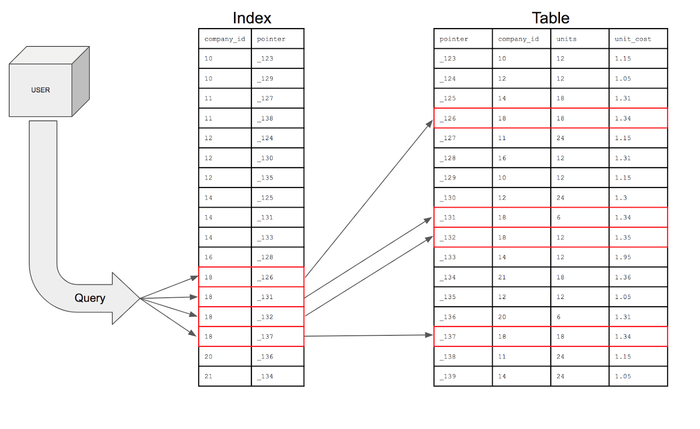
데이터베이스는 B+ 트리 라고 불리는 자료 구조를 사용한다. 카드 더미와 마찬가지로, 키의 범위가 분할되어 데이터베이스가 상대적으로 적은 수의 노드를 검사하여 원하는 값에 도달할 수 있다. 가장 아래에 있는 노드(leaf 노드)에 도달하면 원하는 값이 연결된 키가 있다. (즉, 실제 테이블에서 찾으려고 하던 값 (행)을 더 적은 검색으로 찾을 수 있다)
| 이미지 출처: Database Indexes Explained |
위의 이미지를 보면, 메인 테이블에서 원하는 정보를 찾기 위해 어떤 방식으로 인덱스를 확인하는지 흐름을 볼 수 있다.
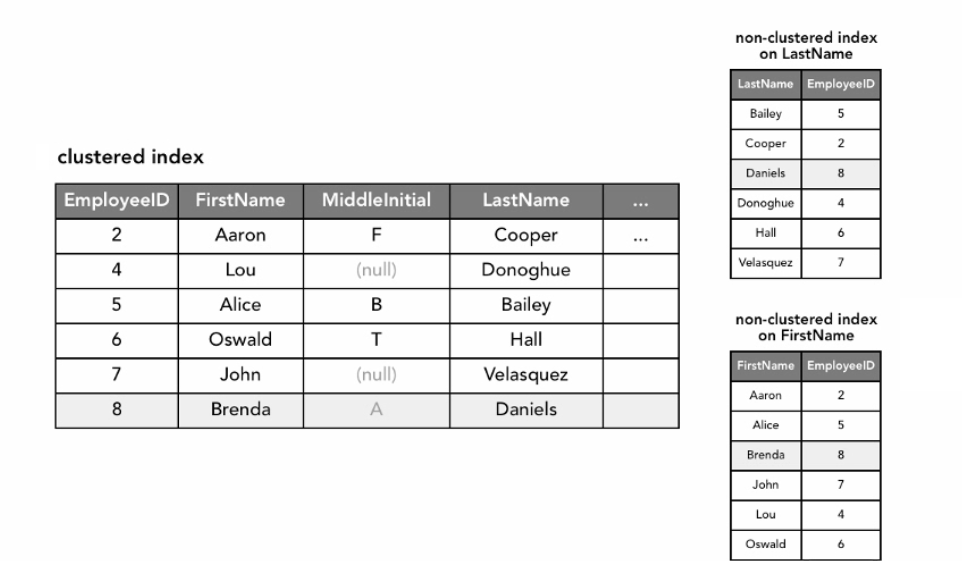
아래 이미지에서는, 실제 테이블이 어떻게 구성되었는지 확인 할 수 있다. 클러스터형 인덱스 테이블은 일반적으로 데이터베이스 테이블로 간주되지만 실제로 정보가 저장되는 방식은 아니다. 테이블을 만들면 기본 키(primary key)에 대한 클러스터형 인덱스가 자동으로 생성된다. 클러스터된 인덱스를 더 잘 통과하기 위한 방법으로 비클러스터된 인덱스를 추가할 수 있다. (클러스터형 및 비클러스터형 인덱스에 대해서는 이 게시글을 참고하자.)
 |
|---|
| 이미지 출처: Database — Indexing, Transactions & Stored Procedures (Part 9) |
인덱싱은 공간을 차지하므로 데이터를 삽입, 편집 및 삭제할 때 마다 유지 비용이 생긴다. 위에서 볼 수 있듯이, 인덱싱이 된 트리는 기본 테이블에 이미 있는 정보를 변형하여 다른 방식으로 구성된다. (새로운 데이터가 생성 되는게 아님). 따라서, 인덱스를 추가하기 전에, 인덱스가 차지하는 공간과 유지 관리 비용이 검색 작업에서 효율적인지 확인해야 한다.
물론 인덱스를 생성하면 검색 속도가 빨라진다는 장점이 있지만, 무분별하게 사용할 경우 오히려 삽입/수정/삭제 성능이 떨어진다는 단점이 있다. 즉, 인덱스는 꼭 필요한 컬럼에만 추가하는 것이 권장된다.
DBMS 의 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 검색하는데는 빠르지만 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문 실행 속도가 느려진다. 결론적으로 DBMS 에서 인덱스는 데이터의 저장 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다. SELECT 쿼리 문장의 WHERE 조건절에 사용되는 칼럼이라고 전부 인덱스로 생성하면 데이터 저장 성능이 떨어지고 인덱스의 크기가 비대해져서 오히려 역효과만 불러올 수 있다. 출처 - Technical Interview Guidelines for Beginners
레일즈에서 인덱스 추가하기
인덱스를 추가하는 가장 쉬운 방법은 마이그레이션을 생성하는 것이다(따라서 테이블 작성을 시작하기 전에 계획을 세우는 것이 중요하다).
- 마이그레이션에서 컬럼 생성 시
:index를 추가해준다.
$ bin/rails generate migration AddPartNumberToProducts
part_number:string:index- 해당 명령어는 아래와 같은 마이그레이션 파일을 생성한다.
class AddPartNumberToProducts < ActiveRecord::Migration[7.0]
def change
add_column :products, :part_number, :string
add_index :products, :part_number
end
end물론, 테이블을 생성한 후에도 인덱스를 수정 / 추가를 할 수 있다.
- 마이그레이션 추가
class AddIndexToTable < ActiveRecord::Migration
def change
add_index :tables, :column_id
end
end- Unique 조건 추가
인덱스가 유일한 값이 될 수 있도록 조건을 추가할 수 있다. 같은 열에 중복되는 값을 넣을 수 없다.
class AddIndexToTable < ActiveRecord::Migration
def change
add_index :tables, :column_id, unique: true
end
end- Unique 조건 심화
JOIN 테이블에서 스코프를 사용해 다중 컬럼에 index를 적용해야 할 때가 있다. 이때, unique 조건이 적용되야 하는 여러 컬럼을 명시해줄 수 있다.
class AddIndexToTable < ActiveRecord::Migration
def change
add_index :tables, [:column_id, :column_2_id], unique: true
end
end인덱스가 필요한 곳을 신중하게 선택해야 한다. 위에서 언급했듯이, 인덱싱은 추가로 공간을 차지하기 때문에 아무 이유 없이 중복 데이터를 저장하는 것을 성능을 저하시킨다. 예를 들어, 폴리모픽(polymorphic) 관계에서 인덱싱을 하는 경우가 있다. (참고: Faster Rails: Is Your Database Properly Indexed?)
왜 인덱스를 써야할까?
결국 인덱싱은 검색 작업의 시간 복잡성을 줄이는 것이다 (= 빠른 검색). 데이터베이스에 인덱스를 추가하는 주된 이유는 자주 검색할 때 속도를 빠르게 하기 위해서이다. 이는 데이터베이스가 클수록 더 큰 성능 차이를 볼 수 있다.
다만, 몇개의 테스트 데이터만 있는 데이터베이스는 너무 작아서 인덱싱의 실제 결과를 볼 수 없다. Api를 이용해 대용량 시드 데이터를 추가 한다던가, 실제로 서비스를 운영한다면 테이블의 적절한 열을 인덱싱하는 것을 고려해야 한다.
속도 외에도, **고유성(uniqueness)**를 보장하기 위해 인덱싱을 활용할 수 있다. 예를 들어, 모델에 **유효성 검증(validation)**을 추가해 이메일이 같은 중복 사용자를 방지 한다고 하자. 이때, 두 명의 사용자가 동일한 시간에 동일한 사용자 이름/이메일을 생성한다면 어떻게 될까? 모델에서 유효성 검사를 수행하려면 두 작업 사이에 일정 시간 이상의 차이가 필요한데, 제대로 검사를 하지 못해 중복 데이터를 생성 할 수 있다.
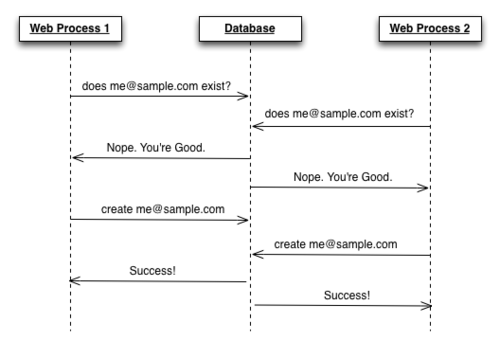 |
|---|
| 이미지 출처: The Perils of Uniqueness Validations |
‘이메일’ 속성을 인덱싱하면 데이터베이스에서 ‘중복되는 이메일’에 대한 저장 작업을 중단할 수 있으므로 두번째 방어선이 제공된다. 인덱싱 덕분에, ActiveRecord는 두 번째 저장 시도 시 오류를 발생시키고 데이터베이스에서 중복된 이메일 사용자를 생성하지 못하게 한다.
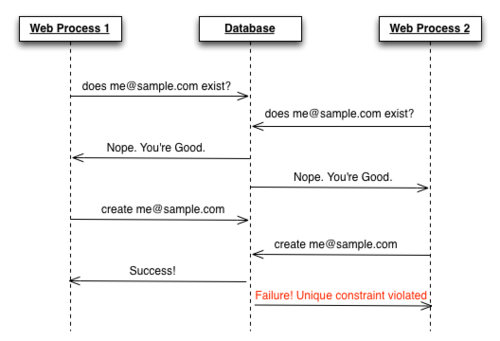 |
|---|
| 이미지 출처: The Perils of Uniqueness Validations |
정리
- 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
- 데이터베이스의 인덱스는 책의 색인과 유사하게 작동한다.
- 자주 검색하는 테이블의 열에 대해 생성해라. (기본키 제외)
- 잘못 사용할 경우, 오히려 성능이 저하될 수 있다.
- 되도록이면 큰 테이블에 적용해라.
- 일부 유효성 검증(validation) 에서 오류를 줄이기 위해 인덱싱이 필요하다.
본 게시물은 What are indexes? And how to add them to your Rails app? 글을 의역한 글 입니다.